

In today’s data-driven world, the reliability of data feeding applications, reports, and tools for rapid decision-making is critical to businesses. Yet, businesses are grappling with major issues around poor data quality and slow issue resolution. Not addressing this can result in lost revenue, missed opportunities, and reputational damage. On the other hand, addressing these fires puts a strain on data engineers and blocks them, and the organization, from advancing strategic data programs.
To more effectively address this problem space, we are excited to begin our data observability journey by introducing data profiling, data quality, and data lineage in Gravity.
Governing Trino at Scale
Starburst was originally known as the Trino company. However, to address the data management and governance challenges with data federation, Gravity was added on top of Starburst Galaxy. This introduced data cataloging, data governance, and data product management capabilities across clouds and sources.
As the surface area of data increases, it becomes evident that data quality and data pipeline hotspots become increasing risks for organizations. While there are ways in which these risks can be evaluated and addressed, they typically require a significant amount of labor and monetary investment in 3rd party tools that may or may not work with the entire data ecosystem.
Starburst has focused on Gravity as an easy way to institute better data practices and governance across your data sources. What better way to help you address data issues than to provide the same ease you’ve come to value with Gravity!
Introducing data observability in Gravity
Enter data observability in Gravity. You can now enable organizations to gain visibility into your data, identify when your data has gone awry, and investigate potential hotspots and blast radius of your data issues easily.
Data observability capabilities built into Gravity means that organizations can now reduce the amount of guesswork and processes to find and resolve data quality issues in a timely manner.
With the introduction of data observability capabilities, your data teams can:
- Gain visibility into the statistics and shape of your data lake tables
- Work with data consumers to define pass / fail quality rules for consumption
- Quickly identify potential origins of issues and downstream impact of the issues
Data Profiling (Public Preview)
Data profiling is a new feature that is being introduced into the Gravity catalog and leverages Trino’s ANALYZE <table> command to generate statistics on Iceberg, Delta, and Hive tables and their columns consisting of
- Number of rows in column
- Null percentages in column
- Unique values in column
- Min / max values in column
Data profiles can be generated simply by selecting a cluster and clicking a button or can be scheduled to run automatically as a cron job. The most recent data profiling output is quickly visible as a summary, plot, and a table of metrics.
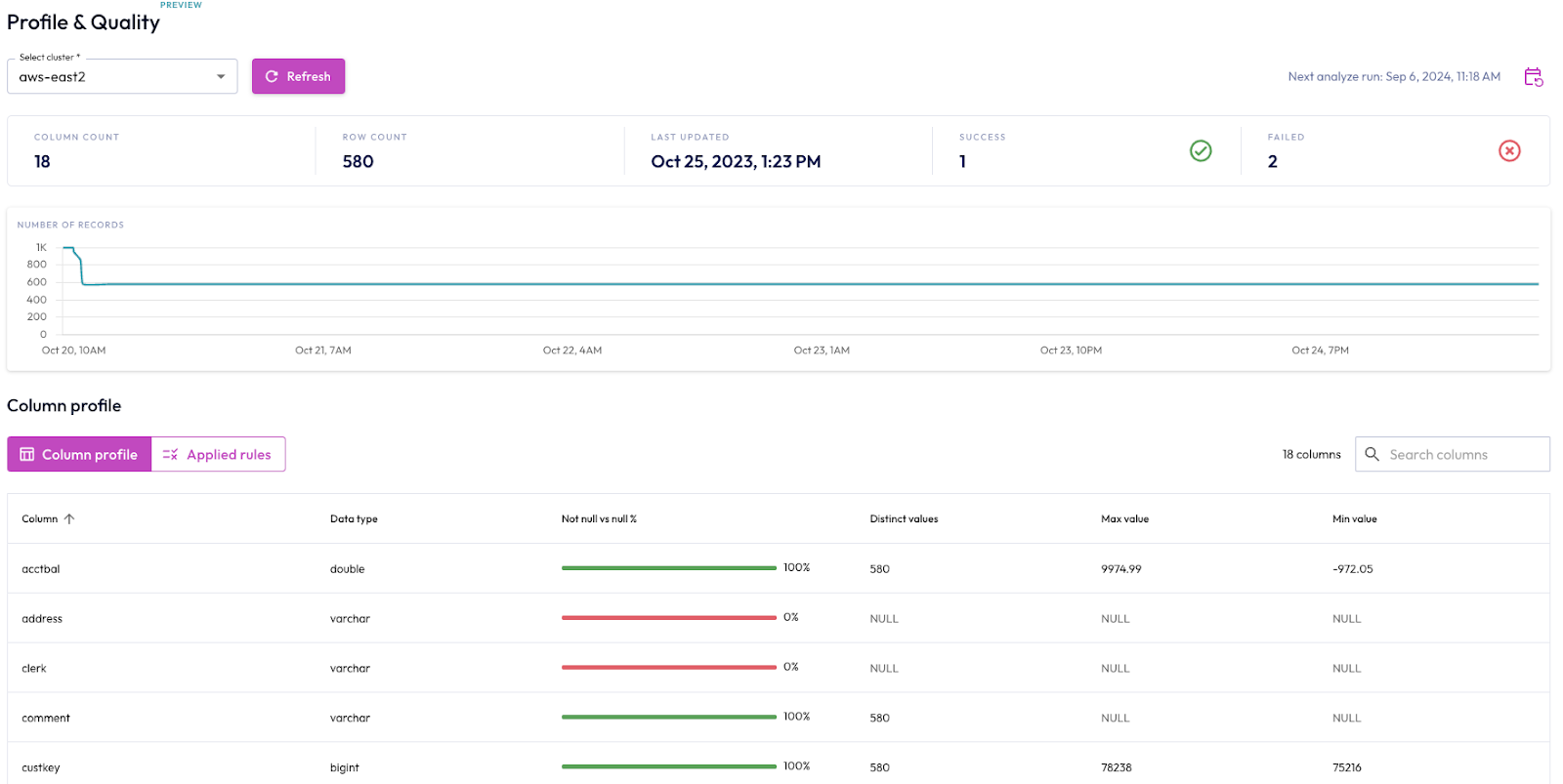
Data Quality (Public Preview)
While data profiling is able to provide an overview of the state of data, by itself it does not provide information about the fitness of data for consumption or whether any data issues need to be addressed. Data quality allows data teams, working in conjunction with consumer teams, to set rules by which the data must abide. These include, but are not limited to maximum null values, allowable value ranges, and rate of change of metrics between profiling events.
A full set of rules can be viewed here.
Boolean clauses (AND, OR, NOT) can be used to create single-column or multi-column rules that allow you and your consumers to define how data should meet their needs and when data quality becomes an issue to resolve by defining the importance or severity of a rule violation.
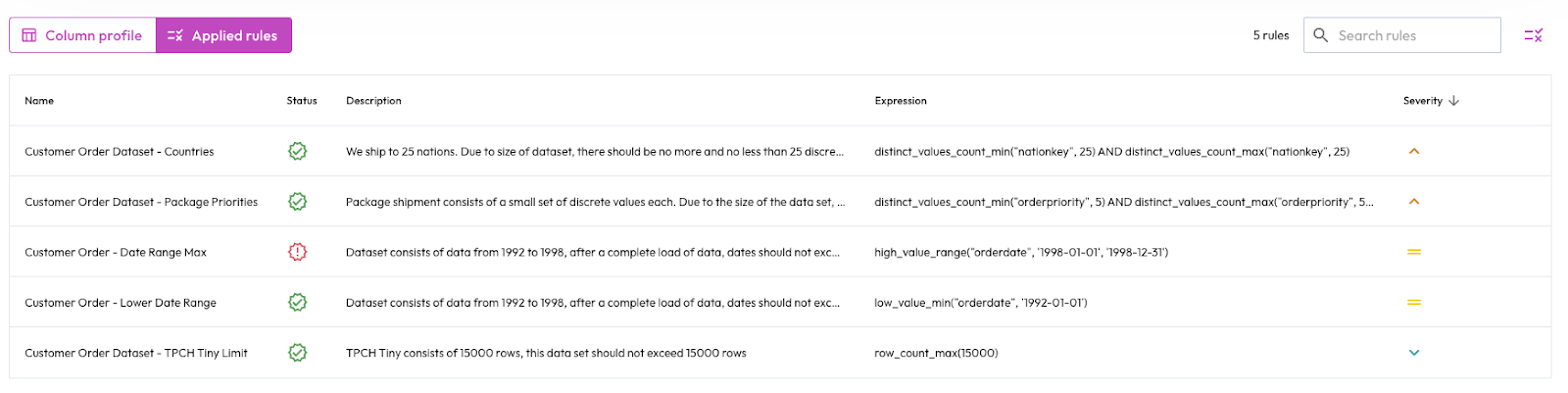
Data quality rules are always checked at the conclusion of data profiling.
Data Lineage (Public Preview)
Data profiling and quality enable you to understand some of the data issues at hand, but can’t help you examine the origin of the issue and potential additional risks these issues may pose. This is where data lineage comes into play.
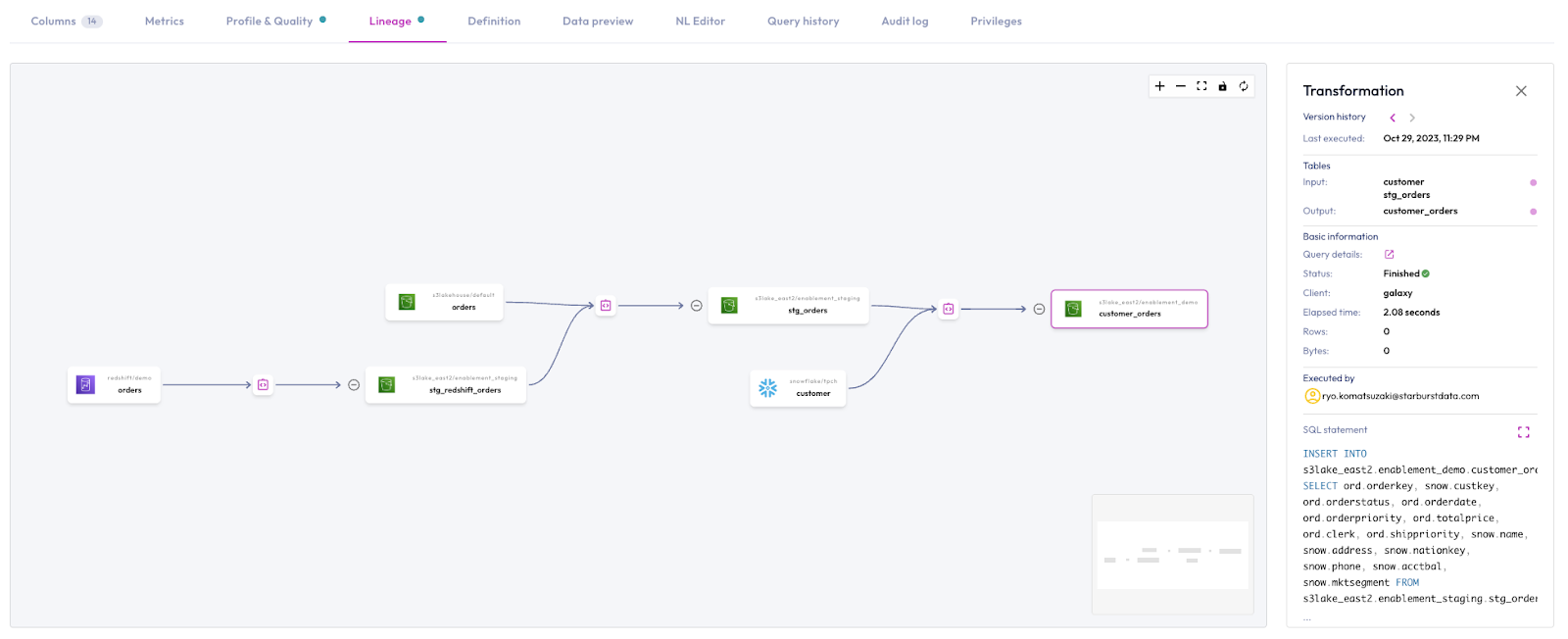
Gravity automatically creates lineage events for workloads carried out in Galaxy with any sources that result in data flow: CTAS, INSERT, UPDATE, MERGE. The lineage tab in the table view automatically renders a navigable map of your data flow and the transformation processes that resulted in your current state of data.
This allows you to identify the origins of your data and the SQL transformations that were executed by Galaxy, and the client responsible for the transformation so you can address issues at the source. Further you will be able to assess the impact of a data issue by understanding how the impacted data is being utilized downstream.
What’s next?
While you may be looking for “data lineage”, “data profiling”, or “data quality” as separate features, we hope we’ve shown how they can be used together as part of a holistic data issue monitoring and resolution flow.
These features are in public preview and available for you to explore as soon as you sign up and connect a catalog to your free account!
A look ahead
We hope the introduction of data observability capabilities across the Galaxy data ecosystem excites you as much as it excites us. The ability to respond to and resolve data issues is critical in this era of data-driven organizations and applications. We believe we are strongly positioned to provide these capabilities while still enabling organizations the optionality to own and manage data where and how you want.
In the coming weeks and months, we’ll be introducing more features and solutions to provide you even more robust capabilities that will be easy for you to use and leverage. With that, I leave you with a sneak peak of what’s to come.
We hope you will join us on this exciting journey!
Get started with Starburst Galaxy
The analytics platform for your data lake




