Dark Data


 BCG study: Data costs & architectural complexity reach a tipping point
BCG study: Data costs & architectural complexity reach a tipping point How to harness a modern data lake architecture within your hybrid environment
How to harness a modern data lake architecture within your hybrid environment Over 80 Data & Analytics Statistics, Data, Trends, and Facts
Over 80 Data & Analytics Statistics, Data, Trends, and FactsDark data is the untapped potential stagnating within enterprise storage systems. Starburst and Red Hat recently sponsored a Boston Consulting Group (BCG) study, “A New Architecture to manage Data Costs and Complexity,” which found much of the data that organizations store is never used and plays no role in decision-making.
Let’s look at what dark data is, why it exists, and how you can leverage the potential sitting in your data repositories to become truly data-driven.
What are examples of dark data? Types and sources of dark data
Dark data can be anything and may be stored anywhere in the company. Without metadata to aid discovery and use, unstructured data is the easiest to lose sight of. However, that doesn’t mean structured data can’t go dark. A database that falls out of use could contribute to your dark data problem.
Looking through your data lakes, shared directories, and user devices will uncover various types of dark data, including:
- System, Web, and App Data
- Network and server log files
- Clickstreams
- Geolocation data
- Business Data
- Customer call center records
- Customer survey data
- Emails, text messages, and social media posts
- Retired databases
- Former employee records
- Operations and Internet of Things Data
- Environmental sensor readings
- Security videos
- Manufacturing quality control images
- RFID records
Why does dark data exist?
The business-critical nature of big data makes dark data inevitable. Since data science is a competitive advantage, the thinking goes, companies are better off generating and storing as much as possible — whether or not they know what to do with all that data. At the same time, more fundamental forces than data hoarding are powering dark data’s growth. Let’s take a closer look at five reasons why.
1. Volume of data is increasing
BCG’s study estimated the amount of data enterprises generate annually will reach 149 zettabytes by 2024. Almost all of this data is unstructured(i.e. video, audio, and text).
Although this vast volume of data may have value, the limitations of storage technologies dictate what businesses can keep. Solid-state storage is expensive, magnetic storage is temporary, and long-lasting film is difficult to access.
As a result, businesses keep the data they think is or might be valuable and throw away the rest. That amounts to only 7% of the data they will generate next year — which is still over 10 zettabytes.
2. Data is more complex
Centuries ago, businesses generated dark data when handwritten documents went missing or disappeared into warehoused file cabinets. Today’s growing data complexity lets dark data grow exponentially.
Data comes from just about anywhere. Every machine a company uses, from printers to microscopes to production lines, is getting networked and connected to the cloud. Internet of Things(IoT) devices monitor environmental conditions and track items through supply chains. And the proliferation of communications channels, from email to Slack to Zoom, is creating more data for companies to store.
Beyond the snowballing sources, the demands of big data mix things up even more. For example, companies adopting the emerging technologies of artificial intelligence and machine learning will create synthetic data to train these systems.
3. Data is siloed
Although centralized data management is a grand theory, it rarely exists in practice. Data storage decisions get made where and when the need is greatest. A manufacturing facility may add another storage server to handle data from a new system. A European subsidiary may spin up a Microsoft Azure Blob to comply with GDPR.
A result of this fragmented storage infrastructure is the creation of data siloes. Metadata standards may vary from silo to silo, and there’s no guarantee that domain owners fully publish their data’s presence to the rest of the organization.
Even if the domain owner understands what data it stores, the data is invisible company-wide.
4. Data velocity is faster
Data flows were almost sedate not so long ago. For example, retail decision-makers didn’t have direct connections to their stores’ point-of-sale (POS) systems. They had to wait for their mainframes to batch-process the day’s POS data.
POS data now flows instantly into retailers’ data warehouses, along with real-time data from a growing number of websites, sensors, trackers, and other systems.
Another factor accelerating data velocity is the way data generates more data. A visitor to a website spawns dozens of new data points, from IP addresses to geolocation data, with every click and page visit.
Our study found that only a tiny fraction of this data enters the company’s storage systems. What survives may never be used unless business processes can keep up with the speed of data.
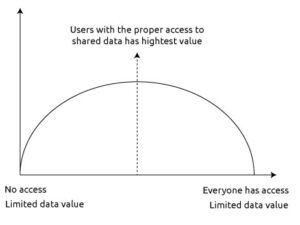
5. Data sharing is critical with data governance
Data governance is a prerequisite for data-driven businesses. Keep in mind, however, access controls may protect regulated or sensitive data but may put data out of reach for data consumers.
Also, business intelligence analysts can’t use data when they don’t understand its metadata or confirm lineages. Moreover, reserving data for a select few data scientists and data engineers doesn’t set the foundation for optimal data use and performance.
Data-driven cultures require a balance that gives the right users access to the right data. Bottom line: managing data poses an enormous challenge, but also a tremendous opportunity. Data alone isn’t valuable. It’s only users with the right access is when data has the most value and potential.
How can we find dark data?
Dark data is one of the nicer data challenges to have. You don’t have to spend money acquiring the data or expanding your data repositories. The data is right there — you just have to look for it.
Starburst’s data lake analytics platform simplifies dark data recovery initiatives by letting you create warehouse-like capabilities right on your data lake. When you activate all the data in and around your data lake, your dark data becomes accessible through our simple SQL query tools.
Access: Single point of access and governance for all your data
Rather than creating yet another centralized data storage asset, Starburst lets you connect users to data sources in every domain through a single point of access. Data storage decisions remain in the domain where they matter most. At the same time, users anywhere can access data without worrying about siloes.
Separating access from data sources makes governance easier. Applying security frameworks within Starburst lets you control access to data, enforce company policies, and improve regulatory compliance.
Scalability: Operate efficiently and reliably at internet scale
Driving data literacy throughout a company runs into constraints within the data teams. Engineers do not have time to support every potential data consumer the way they do for the organization’s data scientists.
Starburst eliminates this constraint by supporting self-serve data consumption models. Our easy-to-use interface and simple SQL-based query tools let data consumers analyze data from anywhere in the company on their own without asking data teams for help. The productivity benefits of democratized access also apply to data engineers who have more time available to support complex analytical projects.
Starburst’s single point of access, combined with automations, further boosts engineering productivity. Engineers will spend less time developing customized extract, transform, load (ETL) and extract, load, transform (ELT) pipelines. Even as data volumes and complexity scale, they have fewer pipelines to create and fewer to maintain.
Optionality: No vendor lock-in
Starburst’s data lake analytics platform integrates with over fifty enterprise data sources, from IBM Cloud to Microsoft Azure to Amazon Redshift. Because we separate storage from compute, you can choose the data storage vendors that make the most sense for domains and use cases.
Not only do you avoid vendor lock-in, but you avoid lock-in transparently. Your data consumers don’t need — or want — to know the details of your storage infrastructure. They just want to run their numbers.
By separating storage from compute and the user experience, Starburst helps eliminate the many headaches of migrating to a new storage vendor.
Query engine: Reduces data movement delays and cost
Starburst’s single point of access lets you turn a fragmented and siloed storage infrastructure into a federated architecture that significantly reduces data movement, copying, and ETL development.
Consider what it takes to build a data product in traditional infrastructure. It requires several one-off ETL pipelines that move or copy data from each source. These pipelines feed interim datasets that engineers must process to support the final data product.
Since Starburst’s flexible query engine lets you access data from every source directly, your engineers can skip the workarounds and focus on delivering the data product.
