Data Warehouse Architecture


 GigaOm TCO report: Starburst data lakehouse enables 3x faster time to insight at half the cost
GigaOm TCO report: Starburst data lakehouse enables 3x faster time to insight at half the cost BestSecret’s data journey: Moving beyond Snowflake
BestSecret’s data journey: Moving beyond Snowflake The difference between a data lake and data warehouse
The difference between a data lake and data warehouseLet’s explore data pipelines and their use in data warehouses. Businesses use data pipelines in different ways, so we’ll also explore the variation in data pipeline architecture, including some common use cases for different scenarios.
Data pipelines with a data warehouse
A data pipeline consists of two main steps. The first step is the ETL pipeline, in which data is moved into a data warehouse from any source data system via a process known as Extract, Transform, and Load (ETL). This step is critical because the data that resides in data warehouses must follow the schemas and use the file formats chosen by the data warehouse architect to fulfill the business’ needs. This means that datasets from different sources, each containing different file structures, may need to be processed in different ways to ensure that they fit the data warehouse’s schema.
The second step in the process is data consumer usage. In this step, data stored in a data warehouse is accessed by end data consumers. This process usually involves Business Intelligence (BI) tools or other integrations. Business analysts use these tools or integrations to query and display data and use it to create reports and derive insights. These big data insights are then used by business analysts and others to answer business questions, improve decision-making and predict future trends.
In the image below, we explore the way a data pipeline is used with a data warehouse.
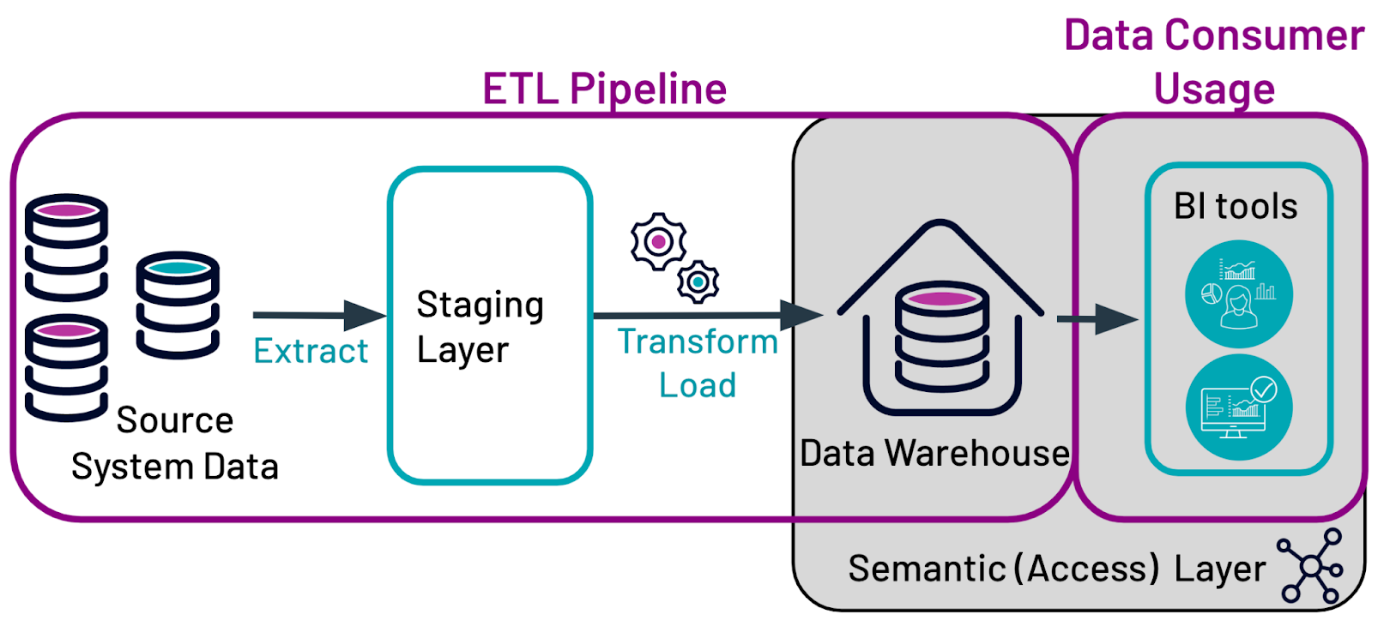
Source system data
The data entered into a data warehouse can be extracted from multiple sources. Most frequently, the data comes from either a transactional or operational database where data is captured. For example, data might come from Internet of Things (IoT) devices, mobile, or online systems. This is made possible by the data model, which defines how data is organized and structured within the warehouse.
Extract
This process extracts data from the source systems and moves it to the staging layer. The data moved into the staging layer is usually a copy of the original data.
Staging layer
The staging layer (or area) is where the copied data resides before it is transformed and loaded into the data warehouse. The staging layer is important because it ensures two things:
- The source system doesn’t get bogged down by complex queries.
- The source data remains intact and unchanged.
Transform and load
Data is transformed so that it fits the data warehouse’s pre-defined schema, which is based on business needs and the tradeoff between query time and load time.
In some cases, data might only be copied. Other transformations might include cleansing, checking for data quality, filtering, or aggregating data. Once the data has undergone all required transformations, it is loaded into the data warehouse.
ELT is similar to ETL, but the transformation step is performed after the data has been loaded into the target system. This approach can be more efficient as it can use the processing power of the target system to perform the transformation and also allows for the parallelization of data processing tasks, significantly speeding up processing times.
Data warehouse
Once data has been transformed and structured according to predefined schemas, it is stored in the data warehouse.
Semantic (Access) Layer
This layer makes data easier for data consumers to access by translating the names and labels of data in source systems into business-friendly language. Implementation of this layer is flexible, and can be done through:
- The predefined schemas in the data warehouse itself.
- An application on top of the data warehouse.
- Business intelligence (BI) tools.
Often, this layer is implemented through some combination of these three options. This layer may also contain common queries and further transformations that make the data more directly useable.
Business intelligence tools
Data consumers use these tools to access data via the semantic layer. It is then used to build reports and run analyses.
Data warehouses also often provide APIs and apps that enable ad-hoc querying and reporting, enabling users to explore and analyze data as needed.
Common business intelligence tools include Tableau, PowerBI, ThoughtSpot, and Looker.
Data marts as subsets of data warehouses
A data warehouse contains all of an organization’s data. Often, though, data is analyzed at the department level. For example, within one organization Human Resources (HR), User Experience (UX), and Marketing might each employ analysts who specialize in answering questions relevant to their department. Each of these departments has a specific business purpose and set of queries they might run to create the reports and analyses they need.
Data marts provide a solution to this problem. Some departments may build and operate their own data marts independently from the enterprise data warehouse. Alternatively, they might segment the data from a data warehouse into a data mart that holds data specific to a particular department. Data may even be transformed as it is moved from the data warehouse to the data mart so that it can be used to efficiently answer that company’s questions.
Data marts can increase the flexibility of how data in a data warehouse is used but can also increase administration costs and complexity. When organizations use data marts, they can exist between the data warehouse and semantic layer, or they can operate separately and have their own data pipeline.
Data warehouse implementations
Data warehouses are not tied to any particular hardware or software. This means they can be implemented in a wide variety of ways. Here, we explore several different implementation styles, the pros and cons of each, and several examples of data warehouse vendors in the following sections:
1. Data warehouse implementations
2. Adapting to the new data landscape
3. Data warehouse vendors
Historically, data warehouses were implemented through hardware on-site at a company. This is known as on-premises and is frequently shortened to on-prem. Over the last decade, however, cloud implementations of data warehouses have evolved to become the dominant model. Organizations can choose to implement their data warehouse on-prem or in the cloud. Alternatively, they can use a hybrid approach.
Related reading: Cloud data warehouse vs. On-premise data warehouse
Adapting to the new data landscape
While these factors are important to consider, tools like Starburst can work with a wide variety of setups to help you minimize the disadvantages and capitalize on the advantages of either setup. For example, if you have an on-prem data warehouse, Starburst allows you to easily query it alongside your other data, no matter where that data is located.
Additionally, using and storing large amounts of data through a cloud-based vendor pricing can become very expensive. When your data analytics strategy becomes cost-prohibitive, Starburst can help you alleviate that burden by querying your data efficiently and separating compute costs from storage costs.
Data warehouse vendors
These days, most data warehouse vendors that were originally on-prem-only have added cloud data offerings. These include Teradata, Oracle, and SQLServer. Some prominent cloud data warehouse vendors include Snowflake, Amazon Redshift, and Google BigQuery.
Using a data warehouse with a data lake
Data warehouses are an excellent solution to certain business problems and have a place in the world of data analytics even with artificial intelligence and machine learning tools. Essentially, data warehouses are most useful for housing data that has a clear and specific purpose.
What’s more, data comes in many forms and is used in many ways. For this reason, data warehouses are unlikely to serve all of the data storage needs of a business because of their limitations with file types and their inflexibility when it comes to adding new data, real-time data, raw data types to the data warehouse. In particular, many businesses may begin collecting some types of data before they know the business purpose it will serve.
Overall, data warehouses may be most useful when used in conjunction with other data storage solutions, such as data lakes.
