Unstructured Data


 4 Best practices for developing and scaling data products
4 Best practices for developing and scaling data products An Introduction to the Data Mesh Execution Model
An Introduction to the Data Mesh Execution Model Build great data products and reduce cognitive load
Build great data products and reduce cognitive loadUnstructured data, semi-structured data, and structured data are all very different data formats with differences in scalability and real-time data analysis. With the growth of big data and enterprise data, scalability has also become a critical factor in data analysis. Organizations need scalable infrastructure, such as a modern data analytics architecture or cloud-based platforms, to process and store large volumes of data efficiently.
Additionally, real-time data analysis is a competitive advantage. Organizations that are able to collect and process data immediately or near-instantaneously as it is generated will have an edge.
Let’s take a closer look at how unstructured data, semi-structured data and structured data impact an organization.
Examples of unstructured data
Examples of unstructured data and their file formats include:
- text files (.doc, .txt)
- emails
- video files (MP4, AVI, or MOV)
- Photos (jpg, tiff)
- audio files (MP3, WAV, or FLAC)
Imagine a photo album on your phone. It houses many individual files. However, each photo isn’t hierarchically ordered into neatly-structured columns and rows because that’s not the best way to store this kind of data.
Analyzing datasets of this type can often yield rich insights. However, traditional analysis would require massive transformation of the entire dataset upfront.
Why is unstructured data used?
Unstructured data is often difficult to store and analyze, but it can be very valuable to data analytics and data management. Use cases for unstructured data might be:
- Business intelligence
- Customer 360 and sentiment analysis with customer relationship management (crm) data
- Extract and analyze user feedback or analyze user-generated content from social media posts
- Classify images and videos
- Identify patterns in text
- Generate natural language text
What is structured vs unstructured data?
Structured data conforms to a regular, predefined schema. Usually, this pattern is set out in advance before any individual data is ever collected. You can think of this structure as a blueprint that governs the way that data within the dataset is stored.
Unstructured data lacks a predefined format and organization, such as text, images, or social media posts. Structured data, on the other hand, has a predefined structure and follows a consistent schema, like spreadsheets or databases.
Examples of structured data
Examples of structured data include:
- Spreadsheets (Microsoft Excel, Google Sheets)
- relational databases
- pre-defined data models
Structured data is particularly suitable for quantitative data analysis and data mining techniques, as it enables straightforward aggregation, filtering, and manipulation.
Structured data is recorded as a series of columns and rows. Each row represents a different instance, a different individual record. At the same time, each column represents a different attribute of those instances. Structured data makes up a significant amount of the data stored in any database, including a data lake.
The image below shows an example of structured data. Notice how each element in the database is positioned in relation to the other elements. This positioning captures and represents the relation between elements in the real world, and can be adjusted as necessary.
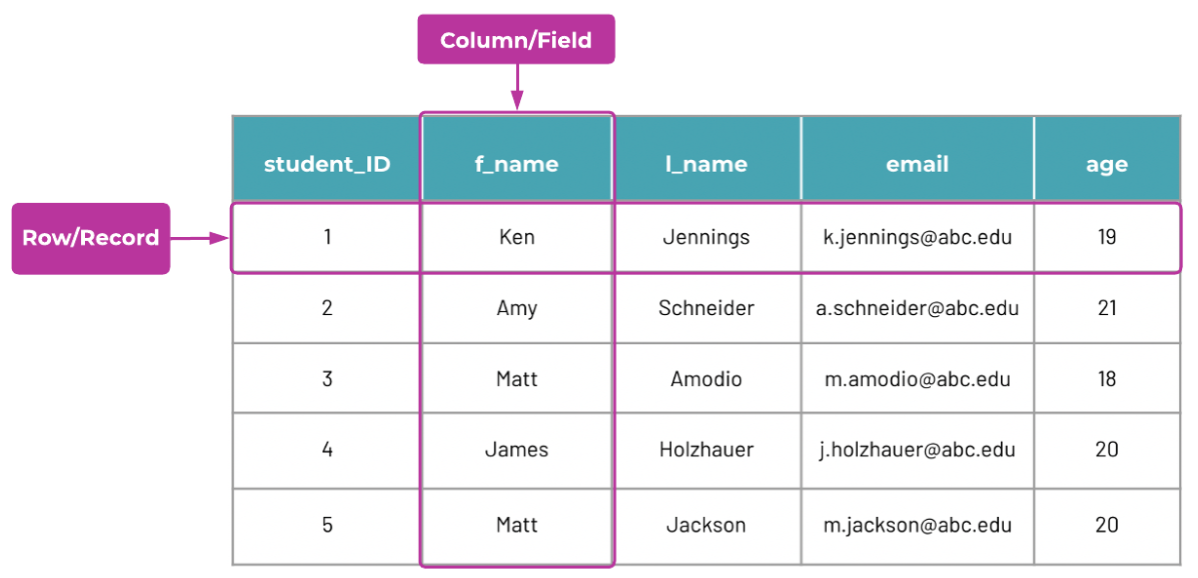
Why is structured data used?
Structured data is powerful and is typically stored in a data warehouse in a tabular format. The data in a data warehouse is typically stored in a relational database management system (RDBMS).
Structure provides certain minimum standards that govern the type of data collected. By recording that data in predefined fields, you can ensure that as much of the data collected as possible is correctly tagged and listed in fields. These divisions can later be used to compare data, or to perform operations. In this sense, the way that you structure data today can help you perform analysis on that data tomorrow.
You create structured data all the time in your everyday life without knowing it. Data lakes make use of structured data to store information from a variety of sources. Imagine that you enter a new contact into your phone. To create the contact, you’ll need to provide some specific information which is entered into fields. This might include a first name, last name, email address, and phone number. All contacts created in the phone require the same information each time a new entry is created. This is structured data at work.
What is semi-structured data?
Datasets can also be semi-structured. Semi-structured does not use tables, rows, or columns. Instead, datasets of this type use tags and markers (i.e. metadata) to achieve some of the same results seen in structured datasets without the same need for a predefined schema. Data lakes are able to store semi-structured data alongside structured data, allowing data from one data type to coexist with data from the other.
Examples of semi-structured data
Examples of semi-structured data and their data formats include:
- Webpages (contains both structured and unstructured dataHTML tags is considered unstructured),
- Social media posts (Unstructured data from social media platforms, such as Twitter, Facebook, or Instagram, is typically stored in formats like JSON (JavaScript Object Notation) or XML (eXtensible Markup Language).
- Log files are generated by systems, apps, or devices to record events or activities.
- IoT (Internet of Things) devices generate vast amounts of data from various sources such as sensor data, devices, and machines. This data is often generated in real-time and can consist of both structured and unstructured information.
You make use of semi-structured data every time you browse the web. Imagine that you are reading the news on a website. When you scroll through the list of articles, you’re viewing data that was retrieved from a database. This data is accessed and displayed by your browser according to predefined rules.
In this model, there is both a backend system storing the information and a frontend system displaying it. Do they speak the same language? Most likely not, but they can store information in intermediate languages like XML and JSON.
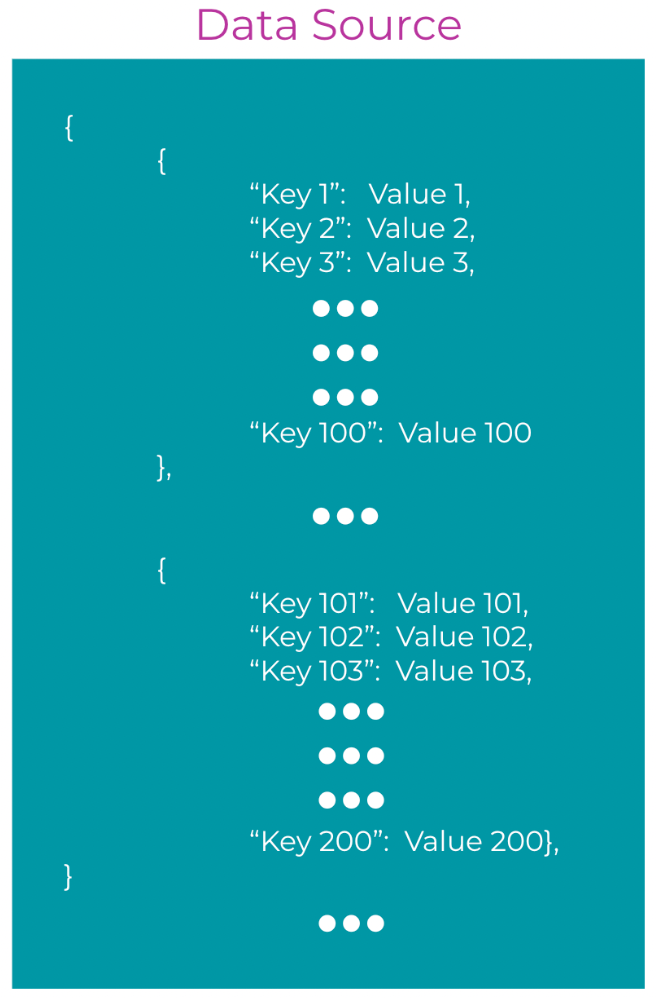
To do this, the data lake holds data as a sequence of data pairings where the data itself is held as a value, and the label for that data is recorded as a key. This structure is known as a key-value pair. Later, when you want to access a particular element’s value, you simply ask the data lake to access the unit of data that corresponds to the required key.
Key-value pairs are a powerful data model and long strings of pairings can be held. Further hierarchy can be introduced by placing one set of key-value pairs inside another, creating a nested, parent-child relationship. This mirrors the function structure found in object-oriented application languages e.g. Java, JS, C++, C#, or Python.
The image below shows a common unstructured data type known as JavaScript Object Notation (JSON). You can see a sequence of key-value pairs, each with their own relation. If a system or user wanted to access Value 3, they would need to input Key 3. Data lakes are particularly good at storing semi-structured data.
Query for unstructured, semi-structured, and structured
Sure, techniques like text mining, and machine learning algorithms, powered by artificial intelligence, are employed to extract meaningful information from unstructured data. However, for now, large language models can be prone to errors. We can’t have our customers making decisions based on bad answers. Your data science teams, data engineers and data scientists won’t be happy about that.
Starburst enables organizations to query data using structured query language (SQL) across various data sources, including unstructured, semi-structured, and structured data.
Here’s how Starburst facilitates querying for each of these three data types:
1. Leverage SQL to query unstructured data and extract relevant information
Unstructured data presents a unique challenge to organizations because it lacks structure, but it also holds immense potential for gaining valuable insights when processed and analyzed effectively.
Starburst can integrate with tools like Apache Hadoop and Apache Kafka, which are commonly used for storing unstructured data. Through connectors and integrations, Starburst can access these data sources and enable SQL-based querying. By defining external tables and schemas, users can leverage SQL to query the unstructured data and extract relevant information.
2. Accessing semi-structured data and use SQL queries
Starburst supports connectors to popular data systems like Apache Hive, and Apache Drill, which are designed to handle semi-structured data. These connectors enable organizations to access the semi-structured data and use SQL queries to extract and manipulate the desired information.
3. Warehouse is a component of a modern data lakehouse
Finally, Starburst can connect to a wide range of structured data sources, including traditional databases like Oracle, SQL Server, MySQL, as well as cloud-native data warehouses like Amazon Redshift, Google BigQuery, and Snowflake. By establishing connections to these sources, organizations can leverage SQL to query and analyze the structured data.
With Starburst, because 80% to 90% of data generated and collected by organizations is unstructured, you can effectively go from a “data warehouse for all your data analytics” to a “data warehouse is a component of a modern data lake.”
